
使用Keda实现Prometheus自动扩缩容
一、Prometheus垂直缩放与水平缩放
在拥有数百个团队的大型组织中,每秒获取数百万个指标是很常见的。通常来说,可以只部署一个Prometheus实例,然后通过增加资源来达到扩展的目的。这通常叫做横向扩展。
但是,这样扩展除需要投入更多资源外,还有一个较大的问题,就是WAL重播问题。
Prometheus 保留一个包含最新抓取数据的内存数据库。为了避免在可能的重启期间丢失数据,Prometheus 在磁盘上保留了预写日志(WAL)。当 Prometheus重启时,它会将 WAL 重新加载到内存中,这样最新抓取的数据就又可用了,这个操作就是我们所说的 WAL Replay。
在 wal 重放期间,Prometheus 完全无法进行查询,也无法抓取任何目标,因此我们希望此操作所用时间越短越好。这就是巨大的 Prometheus实例会产生的问题。当将数百GiB的数据重放到内存中时,这个操作可能需要二三十分钟,更极端的情况下可能需要几个小时。会导致整个监控系统出现较长时间的停机。
避免大型 Prometheus实例的一种常见策略是在多个 Prometheus之间分片抓取目标。由于每个Prometheus都会抓取少量的指标,因此他们会小得多,并且 wal replay 不会像大实例那样成为问题。为了仍然能够将拥有集中式查询体验,可以将指标转发到另一个工具,例如:Thanos、Cortex 或 云提供商,这些工具也可以扩展 Prometheus的查询功能。
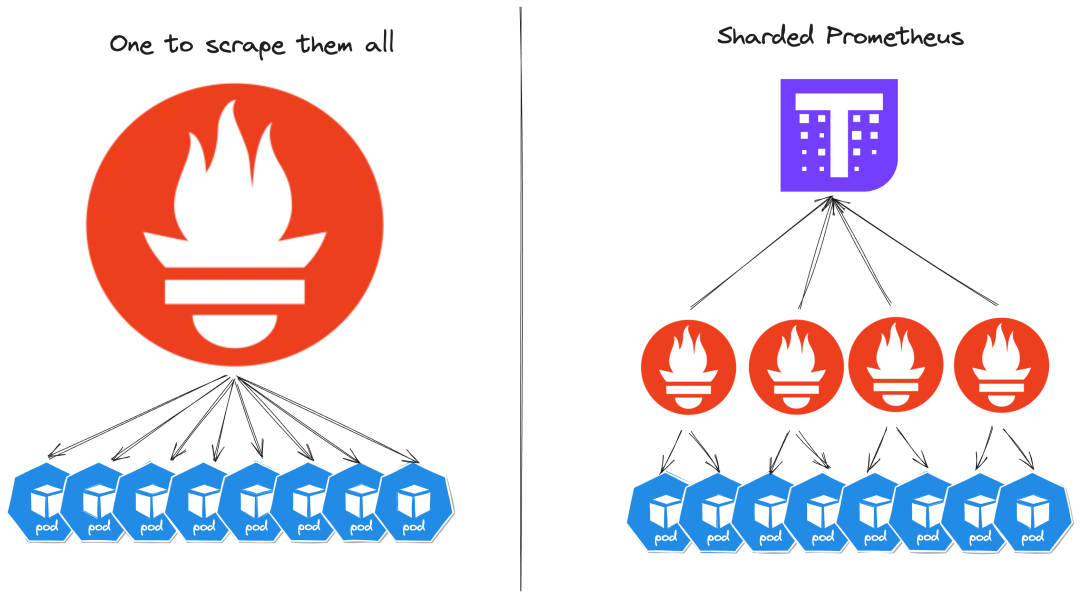
二、整个时间内负载不均匀
我们已经通过使用分片而不是垂直扩展 Prometheus 取得了一些重大进展,但是当暴露的指标数量全天增加和减少时会发生什么?对于每天从数百个节点扩展到数千个节点(反之亦然)的 Kubernetes 集群来说,这是一种非常常见的情况。在决定普罗米修斯碎片的数量时,我们如何找到成本/效益比的最佳点?
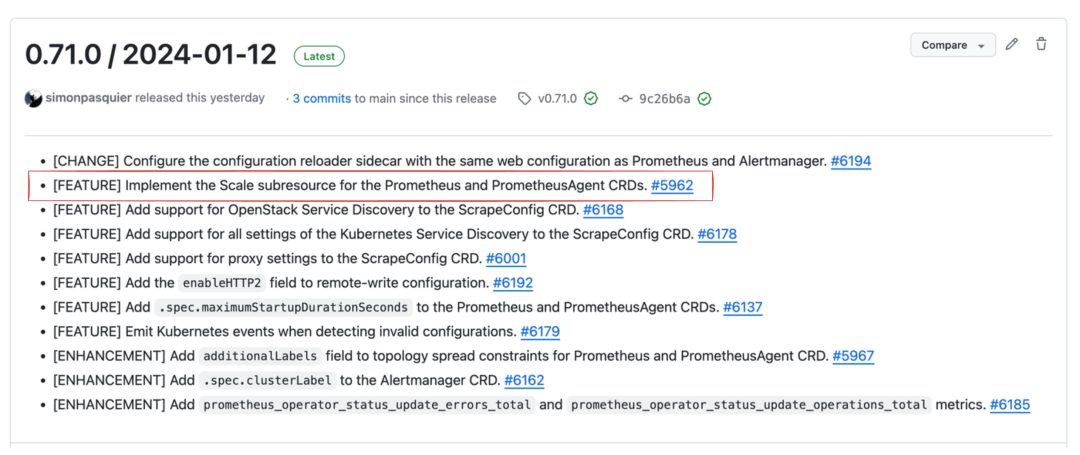
您可以每天手动微调集群中的分片数量,但有更智能的方法来完成此任务。在这篇博文中,我将重点介绍 Horizontal Pod Autoscaler 策略,该策略是最近通过 Prometheus-Operator v0.71.0 版本实现的。
Release 0.71.0 / 2024-01-12 · prometheus-operator/prometheus-operator (github.com)
三、使用 Keda 自动缩放 Prometheus 碎片
这里演示使用 keda进行扩展
1、部署基础环境
- 首先,安装自己的k8s,我这里使用为1.28.2
[root@128-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
128-master Ready control-plane 7d17h v1.28.2
128-node1 Ready <none> 7d17h v1.28.2
# 也可以自己安装其他版本
- 安装keda
[root@128-master ~]# helm repo list
NAME URL
jetstack https://charts.jetstack.io
rancher-stable https://releases.rancher.com/server-charts/stable
[root@128-master ~]# helm repo add kedacore https://kedacore.github.io/charts
"kedacore" has been added to your repositories
You have new mail in /var/spool/mail/root
[root@128-master ~]# helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "kedacore" chart repository
...Successfully got an update from the "jetstack" chart repository
...Successfully got an update from the "rancher-stable" chart repository
Update Complete. ⎈Happy Helming!⎈
[root@128-master ~]# helm install keda kedacore/keda --namespace keda --create-namespace
[root@128-master ~]# kubectl get pods -n keda
NAME READY STATUS RESTARTS AGE
keda-admission-webhooks-b7cc9c84b-k54xd 1/1 Running 0 2m25s
keda-operator-6664786d49-7c5ss 1/1 Running 1 (108s ago) 2m25s
keda-operator-metrics-apiserver-b5c97bbd8-t46b9 1/1 Running 0 2m25s
- 安装Prometheus Operator
[root@128-master ~]# git clone https://github.com/prometheus-operator/prometheus-operator
[root@128-master ~]# cd prometheus-operator
[root@128-master prometheus-operator]# kubectl apply --server-side -f bundle.yaml
2、部署Prometheus及演示程序
2.1、部署alertmanager
[root@128-master test]# cat altermanager.yml
---
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: main
spec:
image: quay.io/prometheus/alertmanager:v0.26.0
podMetadata:
labels:
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
replicas: 1
serviceAccountName: alertmanager-main
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager-main
labels:
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
spec:
ports:
- name: web
port: 9093
targetPort: web
- name: reloader-web
port: 8080
targetPort: reloader-web
selector:
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
---
apiVersion: v1
automountServiceAccountToken: false
kind: ServiceAccount
metadata:
name: alertmanager-main
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: alertmanager-main
spec:
endpoints:
- interval: 30s
port: web
- interval: 30s
port: reloader-web
selector:
matchLabels:
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
[root@128-master test]# kubectl apply -f altermanager.yml
2.2、部署Prometheus
[root@128-master test]# cat prometheus.yml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: k8s
spec:
image: quay.io/prometheus/prometheus:v2.48.1
podMetadata:
labels:
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
shards: 1
serviceAccountName: prometheus-k8s
serviceMonitorSelector: {}
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- apiGroups:
- ""
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- ingresses
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus-k8s
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus-k8s
subjects:
- kind: ServiceAccount
name: prometheus-k8s
namespace: default
---
apiVersion: v1
kind: Service
metadata:
name: prometheus-k8s
labels:
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
- name: reloader-web
port: 8080
targetPort: reloader-web
selector:
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
---
apiVersion: v1
automountServiceAccountToken: true
kind: ServiceAccount
metadata:
name: prometheus-k8s
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: prometheus-k8s
spec:
endpoints:
- interval: 30s
port: web
- interval: 30s
port: reloader-web
selector:
matchLabels:
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
[root@128-master test]# kubectl apply -f prometheus.yml
2.3、查询
# 获取Prometheus地址:
[root@128-master test]# kubectl get svc prometheus-k8s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-k8s NodePort 10.10.94.241 <none> 9090:31139/TCP,8080:30579/TCP 21h
# 我这里的nodeport是 31139,所以我的访问地址为:http://ip:31139
页面访问地址:http://ip:nodeport
如果我们查询指标:
sum(rate(prometheus_tsdb_head_samples_appended_total[2m]))
我们会注意到我们稳定在每秒摄取 40~50 个样本左右。
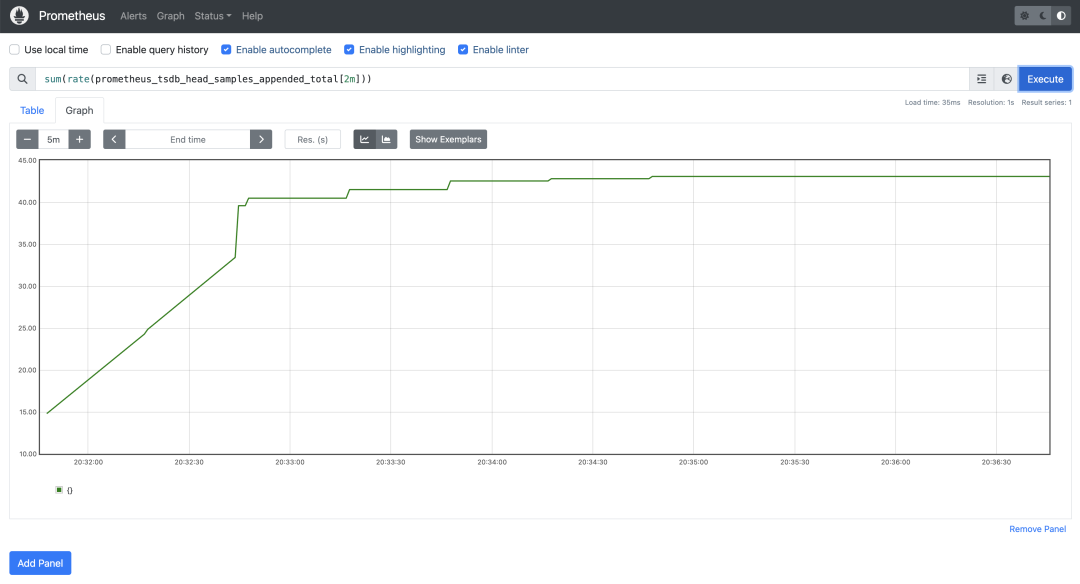
2.4、配置scaledobject
[root@128-master test]# cat scaledobject.yml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus
spec:
scaleTargetRef:
apiVersion: monitoring.coreos.com/v1
kind: prometheus
name: k8s
minReplicaCount: 1
maxReplicaCount: 100
fallback:
failureThreshold: 5
replicas: 10
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-k8s.default.svc.cluster.local:9090
query: sum(rate(prometheus_tsdb_head_samples_appended_total[2m]))
threshold: '200'
[root@128-master test]# kubectl apply -f scaledobject.yml
3、演示扩缩容
# 增加alertmanager pod数量,模拟获取指标数增加
[root@128-master test]# kubectl patch alertmanager main -p '{"spec":{"replicas":20}}' --type merge
alertmanager.monitoring.coreos.com/main patched
# 从页面上查看数据,可以看到,当指标数增加,,Prometheus分片也会自动增加,
[root@128-master ~]# watch kubectl get pods
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 4m8s
alertmanager-main-1 2/2 Running 0 6m52s
alertmanager-main-10 2/2 Running 0 6m52s
alertmanager-main-11 2/2 Running 0 6m52s
alertmanager-main-12 2/2 Running 0 6m52s
alertmanager-main-13 2/2 Running 0 6m52s
alertmanager-main-14 2/2 Running 0 6m52s
alertmanager-main-15 2/2 Running 0 6m51s
alertmanager-main-16 2/2 Running 0 6m51s
alertmanager-main-17 2/2 Running 0 6m51s
alertmanager-main-18 2/2 Running 0 6m51s
alertmanager-main-19 2/2 Running 0 6m51s
alertmanager-main-2 2/2 Running 0 6m52s
alertmanager-main-3 2/2 Running 0 6m52s
alertmanager-main-4 2/2 Running 0 6m52s
alertmanager-main-5 2/2 Running 0 6m52s
alertmanager-main-6 2/2 Running 0 6m52s
alertmanager-main-7 2/2 Running 0 6m52s
alertmanager-main-8 2/2 Running 0 6m52s
alertmanager-main-9 2/2 Running 0 6m52s
prometheus-k8s-0 2/2 Running 0 45m
prometheus-k8s-shard-1-0 2/2 Running 0 3m45s
prometheus-k8s-shard-2-0 2/2 Running 0 2m43s
prometheus-k8s-shard-3-0 2/2 Running 0 2m13s
prometheus-k8s-shard-4-0 2/2 Running 0 71s
prometheus-operator-865844f8b4-ql52h 1/1 Running 0 47m
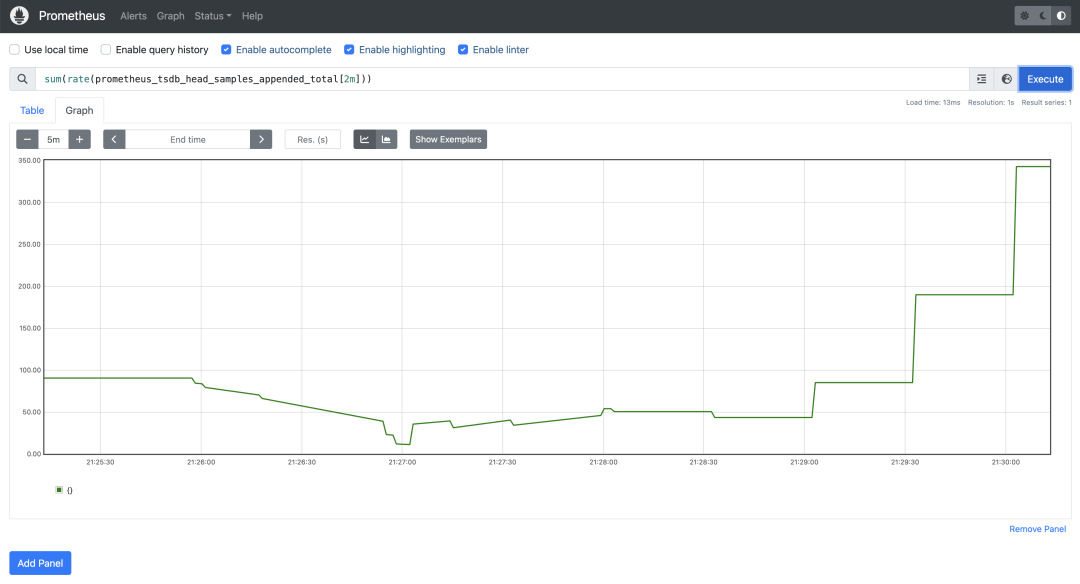
[root@128-master test]# kubectl patch alertmanager main -p '{"spec":{"replicas":1}}' --type merge
alertmanager.monitoring.coreos.com/main patched
[root@128-master ~]# watch kubectl get pods
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 4m51s
prometheus-k8s-0 2/2 Running 0 51m
prometheus-operator-865844f8b4-ql52h 1/1 Running 0 54m